RAG 架构图模板
绘制 RAG 检索管道——查询向量化、向量数据库、检索器、重排序器和 LLM,以及离线数据摄入流程。
使用此模板模板亮点
- 在线查询流程:查询向量化、检索器、重排序器、LLM
- 离线摄入:文档、分块器、Embedding 模型、写入索引
- 向量数据库位于两条流程交汇的中心
这个模板适合做什么
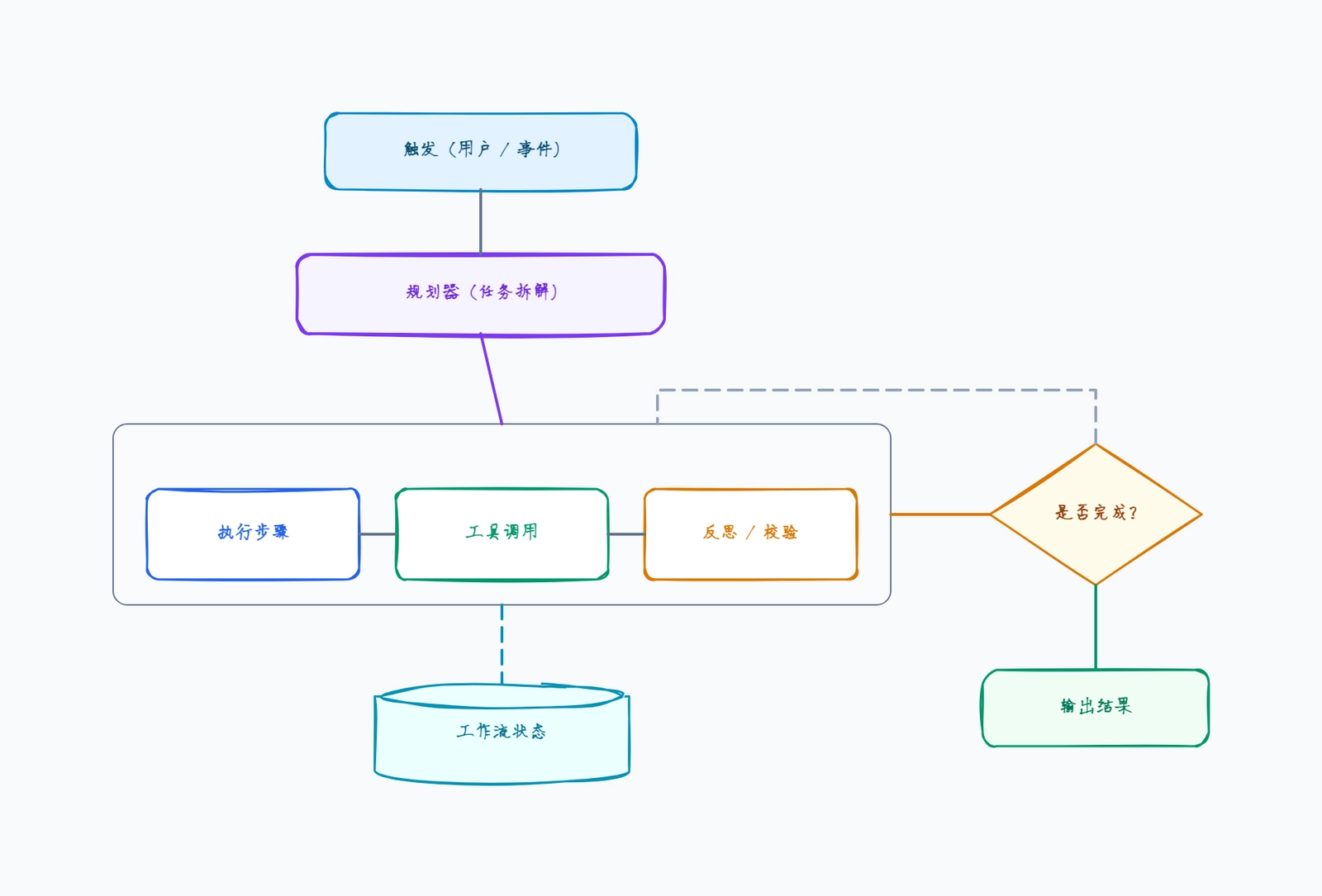
RAG(检索增强生成)架构图展示了语言模型如何借助你自己的数据来回答问题,而不只依赖训练时记住的内容。本模板呈现每个 RAG 系统都有的两条流程:在线查询流程——用户提问 → 查询向量化 → 向量检索 → 重排序 → LLM 生成;以及为知识库做准备的离线数据摄入流程——原始文档被分块、向量化,然后写入向量数据库。适合用于设计新的检索系统、为设计评审整理现有系统文档,或向干系人说明你的 RAG 管道在哪里检索、排序与生成。
适用场景
- 在写代码之前,为新的文档问答系统设计检索管道。
- 为技术评审整理现有 RAG 系统的查询路径文档。
- 向新工程师解释在线查询流程与离线摄入流程的区别。
- 决定在哪里加入重排序器,并展示它如何提升检索精度。
- 通过走完从用户提问到生成回答的完整路径来定位延迟。
- 通过编辑图表,对比简单 RAG 与高级 RAG(混合检索、查询改写)。
使用步骤
- 1从顶部的用户和接收问题的应用 / 聊天 UI 开始。
- 2添加编排器(LangChain、LlamaIndex),它负责协调向量化、检索和 LLM 调用。
- 3绘制在线查询流程:查询向量化 → 检索器 → 重排序器。
- 4在检索器下方添加向量数据库并连接——语义检索就发生在这里。
- 5将编排器连接到根据检索上下文生成最终答案的 LLM。
- 6添加离线摄入流程:文档 → 分块器 → Embedding 模型 → 写入索引。
- 7将摄入的写入索引步骤连到向量数据库,展示知识库是如何构建的。
简单示例
基于企业知识库的文档问答
用户 → 聊天 UI → 编排器(LangChain)
查询:问题 → 查询向量化 → 检索器 → 重排序器 → Top-k 片段
检索器 ↔ 向量数据库(Pinecone)进行语义检索
编排器 → LLM(GPT-4)根据检索上下文生成答案
摄入(离线):PDF → 分块器 → Embedding 模型 → 写入索引 → 向量数据库
在线开始编辑
在 CodePic 中打开模板后,替换示例节点,就能很快整理成自己的学习导图。