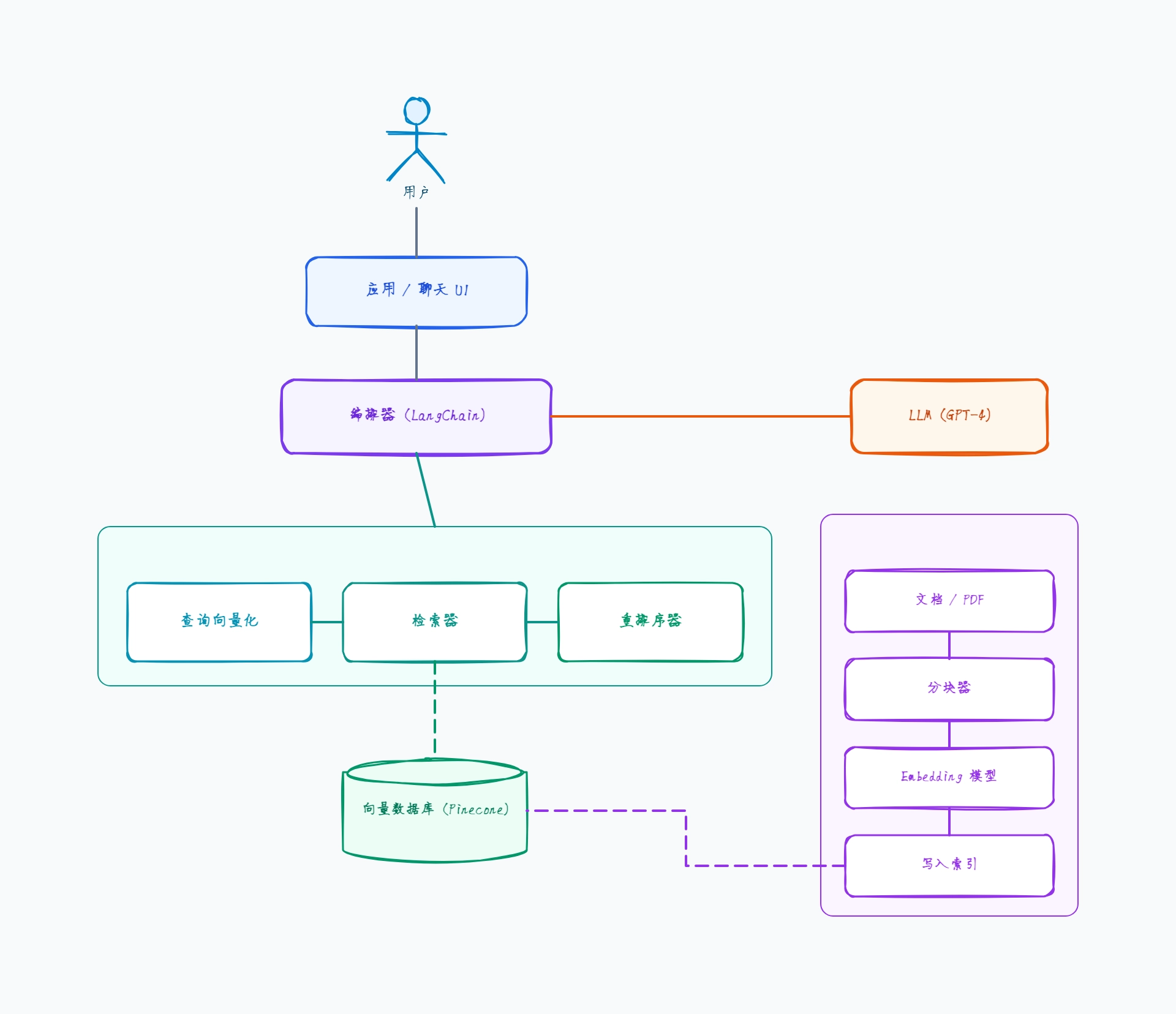
朴素 RAG(基线方案)
使用场景: 构建首个检索原型的开发者
摄入:文档 → 固定大小分块(512 tokens)→ Embedding → Chroma
查询:问题 → Embedding → 向量检索(Top-5)→ LLM
编排器:单条 LangChain RetrievalQA 链
无重排序器、无查询改写——检索到的片段直接进入提示词
LLM:GPT-3.5-turbo,成本更低
这样组织的原因: 朴素 RAG 是最合适的起点——组件最少,所以当答案出错时,你能在增加复杂度之前先判断问题出在检索(取错片段)还是生成(片段对但答案差)。