LLM 微调流程图模板
绘制 LLM 微调流程——数据集准备、分词、LoRA/SFT 训练、评估和部署。
使用此模板模板亮点
- 数据集准备并预处理为模型可用输入
- 用 LoRA 或全量 SFT 微调基座模型
- 评估关卡,循环回训练或部署到仓库
这个模板适合做什么
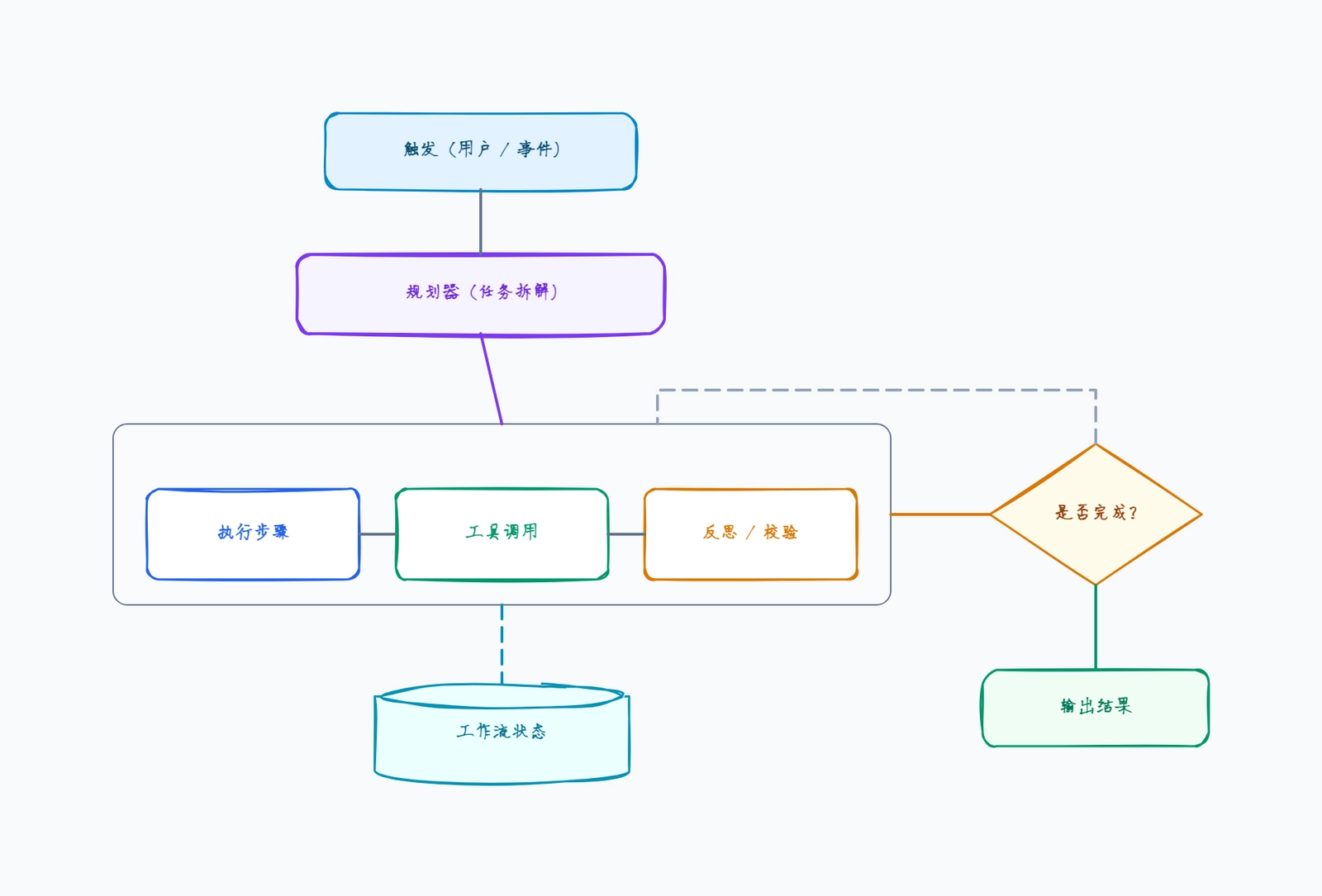
LLM 微调流程图展示了从原始训练数据到部署微调模型的路径。本模板呈现标准阶段:数据集准备、预处理与分词、适配基座模型的微调步骤(LoRA 或全量 SFT)、评估阶段,以及部署到服务端点并带模型仓库。当指标不达标时,评估关卡会循环回训练。适合用于设计微调工作流、为现有训练流水线整理文档,或解释基座模型从哪里进入、评估在哪里把关部署。
适用场景
- 在搭建训练基础设施之前,设计微调流水线。
- 通过指向训练阶段,解释 LoRA 与全量微调的区别。
- 为新 ML 工程师整理现有训练流水线的文档。
- 展示基座模型在哪里加载、适配后的模型在哪里登记。
- 规划决定检查点是发布还是重训的评估关卡。
- 对比微调流水线与 RAG 方案在补充领域知识上的差异。
使用步骤
- 1从数据集准备开始——收集和清洗训练样本。
- 2添加预处理 / 分词,把数据转成模型可用的输入。
- 3添加微调步骤(LoRA 或 SFT),并把基座模型喂进去。
- 4添加评估阶段,用基准衡量微调后的模型。
- 5添加评估关卡:达标 → 部署并登记;不达标 → 循环回训练。
- 6添加模型仓库和服务端点作为部署目标。
简单示例
指令微调流水线
数据集准备:收集指令-回复对,去重、过滤
预处理:分词,格式化为对话模板
基座模型(Llama / Mistral)→ 用 LoRA 微调
评估:基准 + 留出评估集
达标?是 → 登记 + 部署;否 → 调整并重训
在线开始编辑
在 CodePic 中打开模板后,替换示例节点,就能很快整理成自己的学习导图。