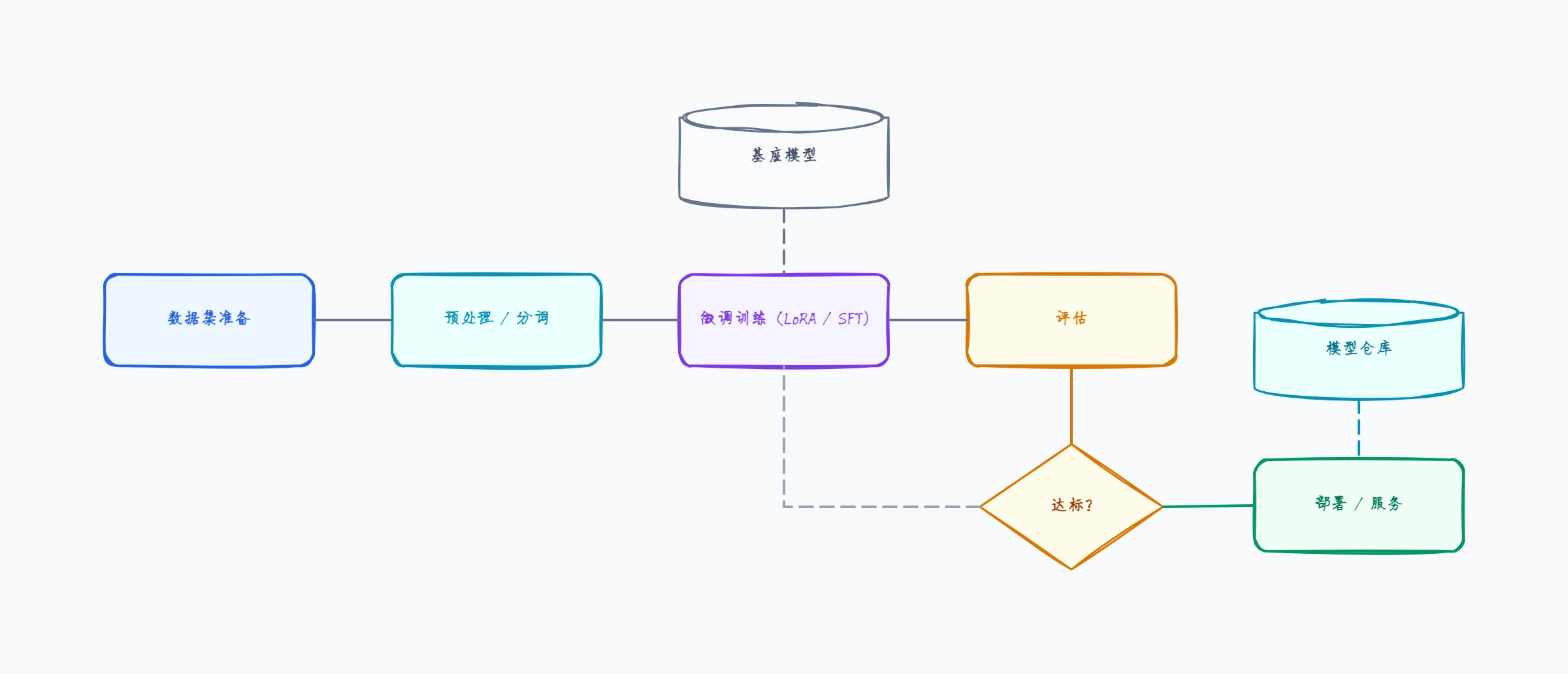
LoRA 微调(参数高效)
使用场景: 在单张 GPU 上微调的开发者
基座模型冻结;只训练小的适配器权重
数据集:几千条任务特定样本
训练可在一张消费级或云 GPU 上完成
输出:小的 LoRA 适配器,而非完整模型副本
部署:服务时加载基座模型 + 适配器
这样组织的原因: LoRA 是最易上手的微调方法——图表展示基座模型冻结、只训练适配器,这正是它能在普通硬件上运行、并产出小而可替换的适配器(而非完整模型)的原因。
使用场景: 在单张 GPU 上微调的开发者
这样组织的原因: LoRA 是最易上手的微调方法——图表展示基座模型冻结、只训练适配器,这正是它能在普通硬件上运行、并产出小而可替换的适配器(而非完整模型)的原因。
使用场景: 有预算更新全部模型权重的团队
这样组织的原因: 全量 SFT 更新每个权重——图表增加检查点和回归评估,因为改变所有参数有损害基座模型通用能力的风险,必须在部署前衡量。
使用场景: 把模型对齐到人类偏好的团队
这样组织的原因: 偏好微调在 SFT 之后增加第二个训练阶段——图表展示偏好数据和奖励信号,因为对齐到人类偏好与模仿示范是不同的目标。
使用场景: 随新数据到来而重训的团队
这样组织的原因: 持续微调闭合了从生产回到训练的循环——图表增加反馈路径和冠军-挑战者关卡,于是新模型只有在可衡量地胜出时才替换线上模型。
回到模板页,直接替换成你的课程主题、章节和复习重点,就可以继续使用这套结构。
使用这个模板: /editor/new?template=llm-fine-tuning-pipeline
编辑此微调流程图模板