生产事故响应
使用场景: 值班工程或 SRE 团队
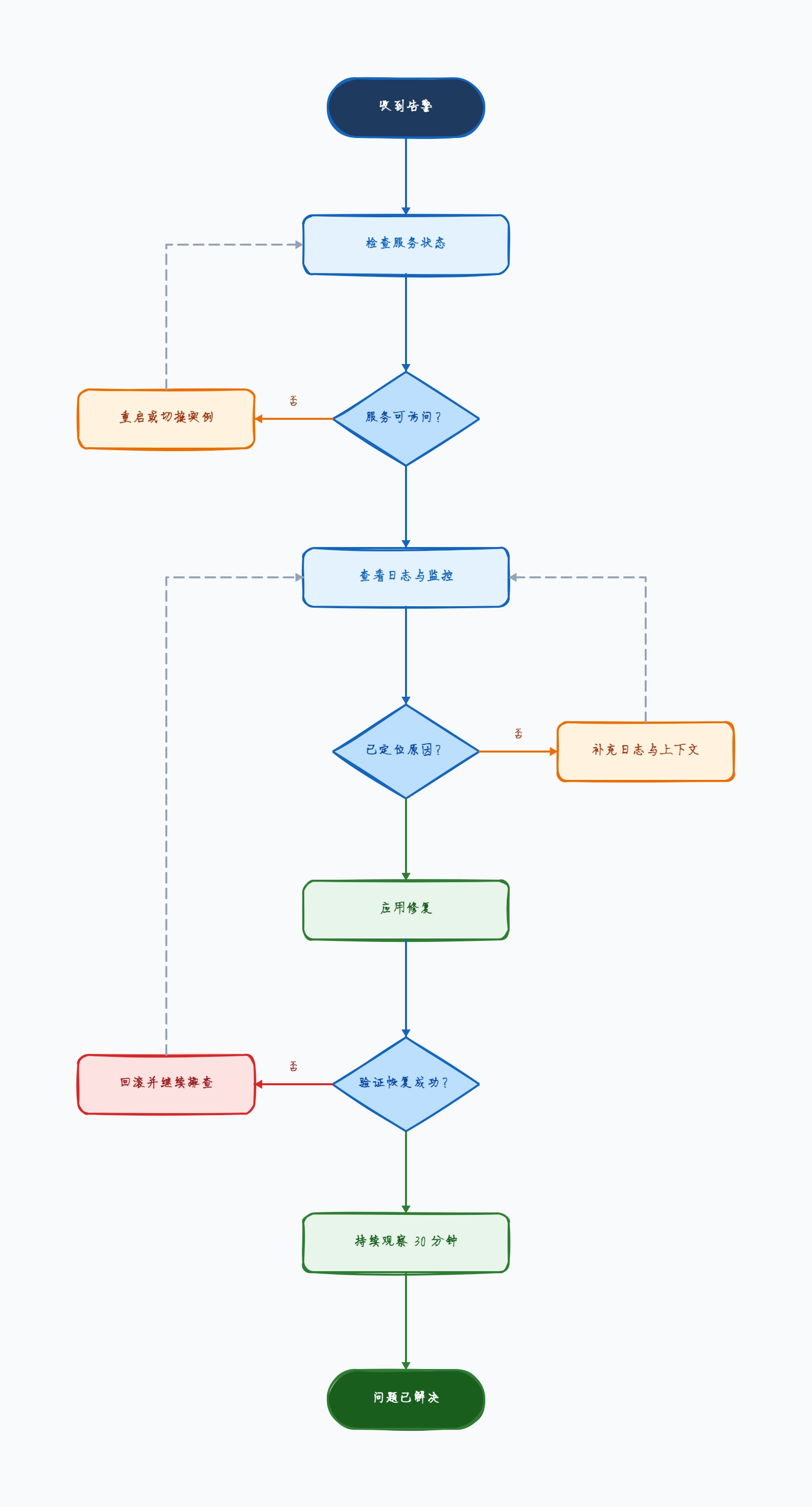
告警触发
→ 服务可访问?
否 → 重启 / 切换实例
是 → 查看日志与监控
→ 已定位原因?
否 → 补充证据
是 → 应用修复 → 验证 → 观察 → 结束
这样组织的原因: 这个结构把“先恢复”与“深挖根因”分开了,能同时兼顾恢复速度和排查质量。
使用场景: 值班工程或 SRE 团队
这样组织的原因: 这个结构把“先恢复”与“深挖根因”分开了,能同时兼顾恢复速度和排查质量。
使用场景: 支持团队,处理重复出现的产品问题
这样组织的原因: 最大的价值是统一前置信息收集方式,让升级前不再遗漏关键上下文。
使用场景: 产品或平台团队,排查回归问题
这样组织的原因: 把环境对比和回滚留在图里,能避免团队只盯着代码本身,忽略环境和发布因素。
回到模板页,直接替换成你的课程主题、章节和复习重点,就可以继续使用这套结构。
使用这个模板: /editor/new?template=troubleshooting-flowchart
使用这个排障模板