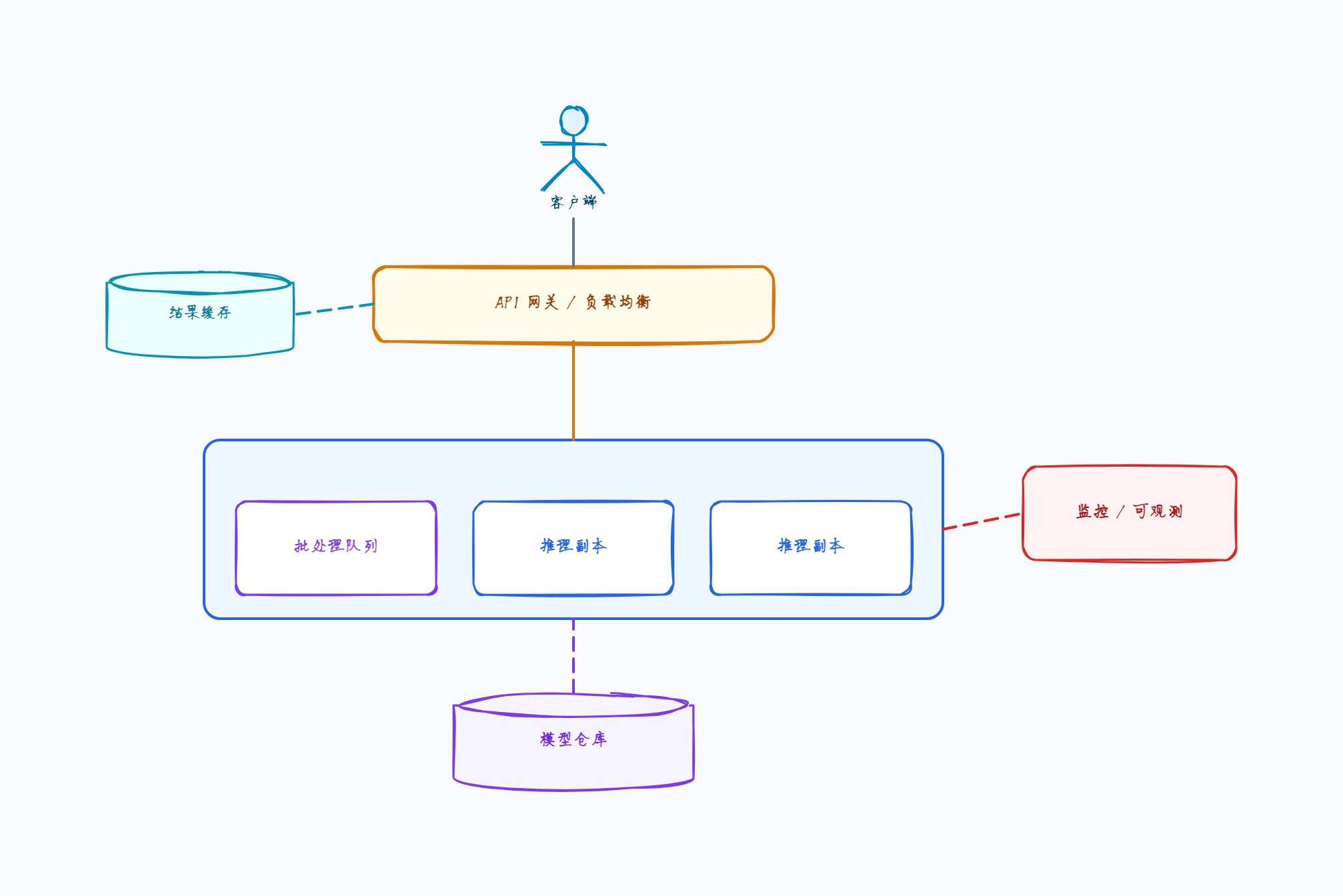
单副本(基线方案)
使用场景: 部署首个模型端点的开发者
一个推理服务位于简单反向代理之后
启动时从仓库一次性加载模型
同步请求 → 预测 → 响应
无批处理;一次一个请求
基础健康检查和延迟日志
这样组织的原因: 单副本是最简单的服务配置——图表没有批处理队列或负载均衡,因为一个服务串行处理请求,低流量时没问题,但无法扩展或批处理。
使用场景: 部署首个模型端点的开发者
这样组织的原因: 单副本是最简单的服务配置——图表没有批处理队列或负载均衡,因为一个服务串行处理请求,低流量时没问题,但无法扩展或批处理。
使用场景: 服务可变生产流量的团队
这样组织的原因: 自动扩缩集群是生产标准的服务模式——图表增加批处理队列和自动扩缩器,因为批处理最大化 GPU 效率,自动扩缩让副本数匹配负载。
使用场景: 用一套机群服务多个模型的团队
这样组织的原因: 多模型服务器把多个模型整合到共享基础设施上——图表在网关增加模型名路由,于是一套机群服务多个模型,而非每个模型一套部署。
使用场景: 服务大语言模型的团队
这样组织的原因: LLM 服务用连续批处理取代静态批处理,并增加 KV-cache 和流式——图表反映生成是逐 token 的,于是服务层必须管理进行中的序列,而非离散的请求-响应对。
回到模板页,直接替换成你的课程主题、章节和复习重点,就可以继续使用这套结构。
使用这个模板: /editor/new?template=model-serving-architecture
编辑此模型服务模板