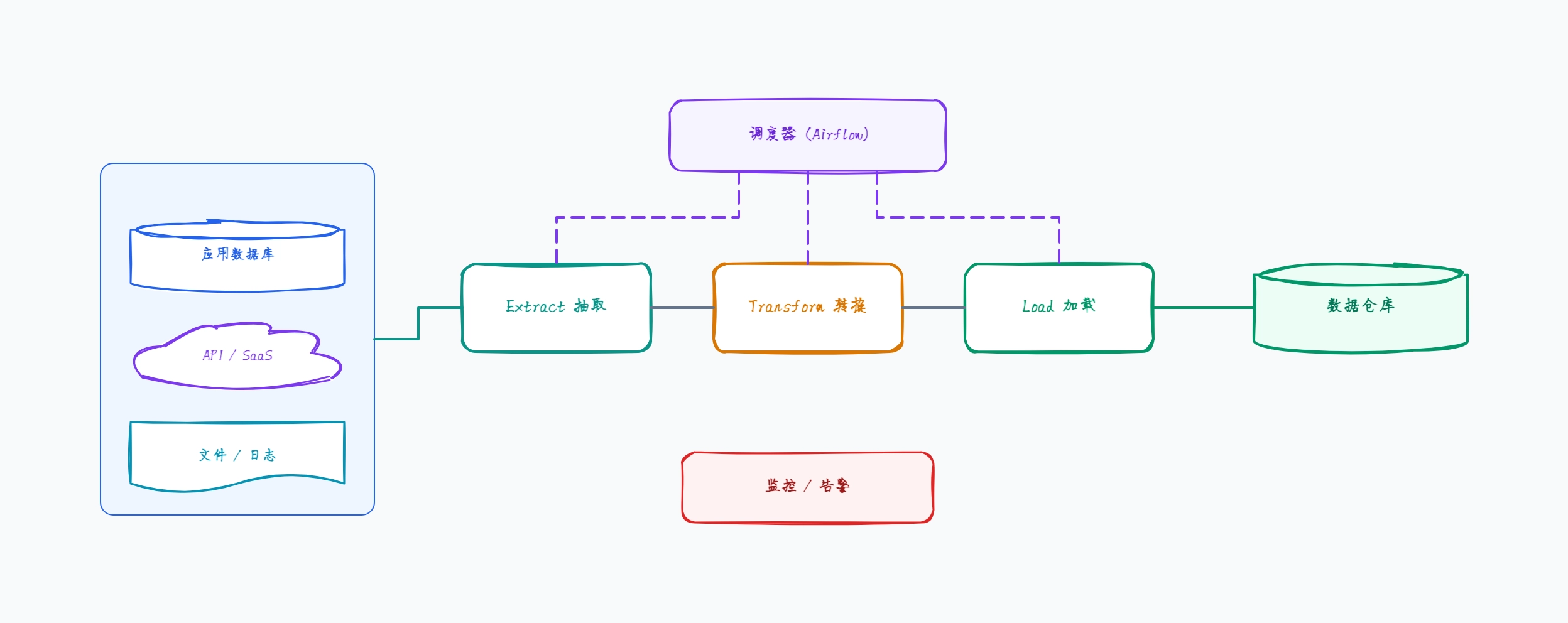
经典批 ETL(基线方案)
使用场景: 构建首个分析管道的团队
定时按小时或夜间运行
从源抽取到 staging 区
在管道中转换(Spark、Pandas、加载前 dbt 模型)
仅把干净、建模过的数据加载进仓库
仓库保持小而干净
这样组织的原因: 经典批 ETL 在加载前转换——图表把转换作为独立阶段,让仓库保持精简,但把复杂度推给管道工具。
使用场景: 构建首个分析管道的团队
这样组织的原因: 经典批 ETL 在加载前转换——图表把转换作为独立阶段,让仓库保持精简,但把复杂度推给管道工具。
使用场景: 使用 Snowflake / BigQuery / Redshift 的团队
这样组织的原因: ELT 颠倒顺序——图表把 Load 放在 Transform 之前,转换阶段住在仓库里。这能工作是因为现代云仓库在规模上让转换变得便宜。
使用场景: 需要近实时数据的团队
这样组织的原因: 流式用持续运行的管道取代批调度器——图表去掉调度器框、加入流处理引擎,因为新鲜度要求把架构从定期批处理推向常开式流动。
使用场景: 把业务库同步进仓库的团队
这样组织的原因: CDC 消除定期完整抽取——图表用变更日志读取器替代 Extract 阶段,让仓库保持同步而无需扫描源表。
回到模板页,直接替换成你的课程主题、章节和复习重点,就可以继续使用这套结构。
使用这个模板: /editor/new?template=etl-pipeline-architecture
编辑此 ETL 模板