Naive RAG (the baseline)
Who uses it: Developer building a first retrieval prototype
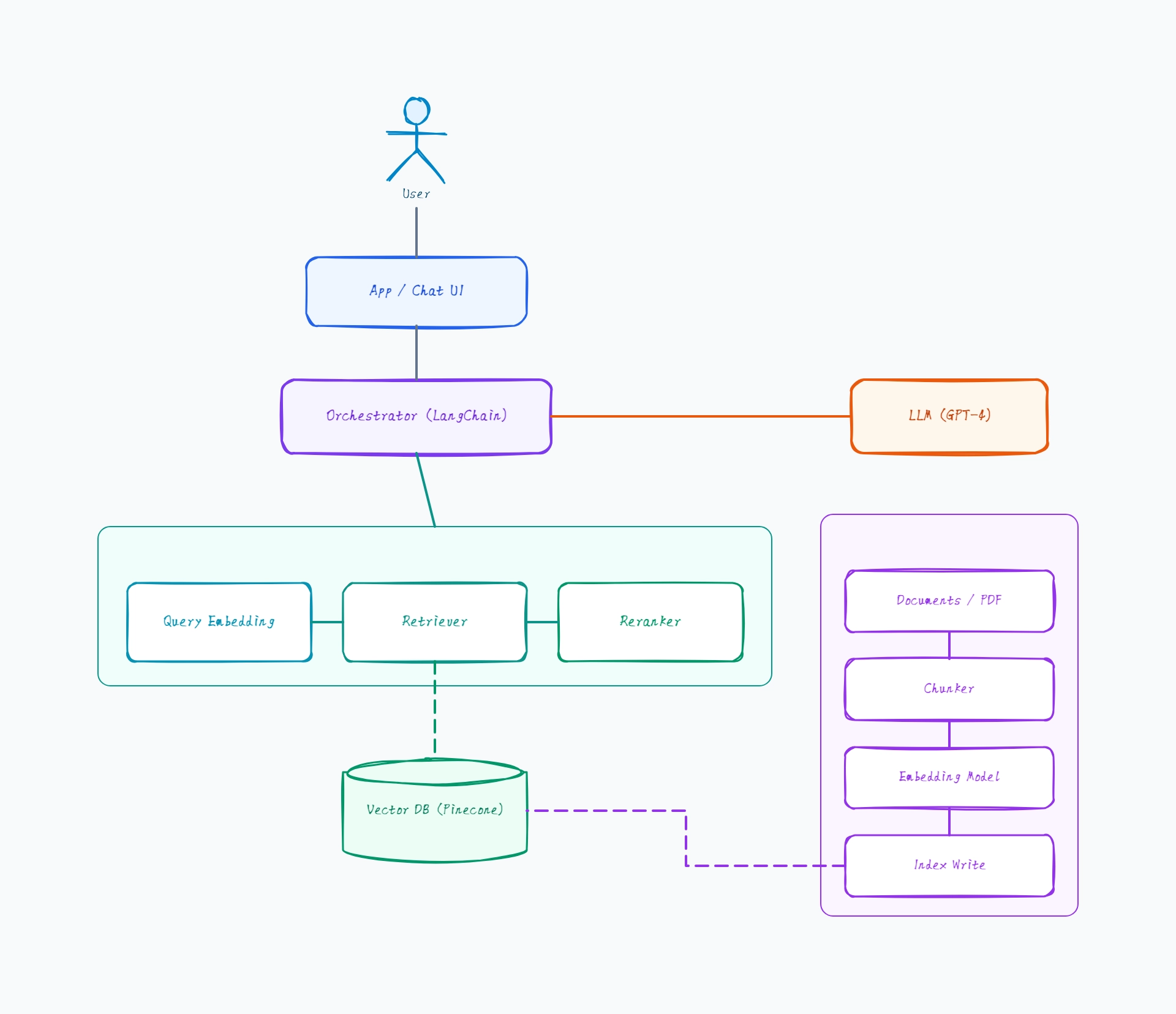
Ingestion: docs → fixed-size chunker (512 tokens) → embedding → Chroma
Query: question → embedding → vector search (top-5) → LLM
Orchestrator: a single LangChain RetrievalQA chain
No reranker, no query rewriting — retrieved chunks go straight to the prompt
LLM: GPT-3.5-turbo for low cost
Why this works: Naive RAG is the right place to start — it has the fewest moving parts, so when answers are wrong you can tell whether the problem is retrieval (wrong chunks) or generation (right chunks, bad answer) before adding complexity.
RAG with reranking
Who uses it: ML engineer whose answers are missing relevant context
Query: question → embedding → vector search (top-20) → reranker → top-5 → LLM
Reranker: a cross-encoder (Cohere Rerank or bge-reranker) scores each candidate
Vector DB: Pinecone with metadata filters by document source
Why top-20 then rerank to 5: cast a wide net, then keep only the best
Orchestrator: LangChain with a ContextualCompressionRetriever
Why this works: Adding a reranker is the highest-leverage upgrade to a naive RAG system — vector search alone optimizes for similarity, but a cross-encoder reranker actually reads the query against each chunk and reorders by true relevance.
Hybrid search RAG
Who uses it: Team where keyword-exact queries (product codes, names) fail semantic search
Query runs two retrievers in parallel: dense (embeddings) + sparse (BM25)
Results merged with Reciprocal Rank Fusion before reranking
Vector DB: Weaviate with built-in hybrid search, or Pinecone + Elasticsearch
Ingestion indexes both embeddings and a keyword index
Reranker fuses and reorders the combined candidate set
Why this works: Hybrid search fixes the classic RAG failure where a user searches an exact term — a SKU, an error code, a person's name — and pure semantic search returns 'similar' but wrong results. BM25 catches the exact match, embeddings catch the meaning.
Agentic RAG
Who uses it: Developer building an assistant that decides when and what to retrieve
Orchestrator: a ReAct agent that chooses whether retrieval is even needed
Agent can rewrite the query, retrieve, then decide to retrieve again
Multiple sources: vector DB + SQL database + web search as separate tools
Self-check step: agent verifies retrieved context answers the question
Falls back to a clarifying question if retrieval confidence is low
Why this works: Agentic RAG moves the retrieval decision into the LLM itself — instead of always retrieving, the agent reasons about whether it needs external data, which query to run, and whether the results are good enough, trading latency for accuracy on complex questions.