Model Serving Architecture Diagram Template
Diagram a model serving stack — gateway, inference cluster, batch queue, model registry, cache, and monitoring.
Use this templateWhat you get
- API gateway / load balancer in front of inference replicas
- Batch queue and model registry feeding the serving cluster
- Result cache and monitoring across the request path
What this template is for
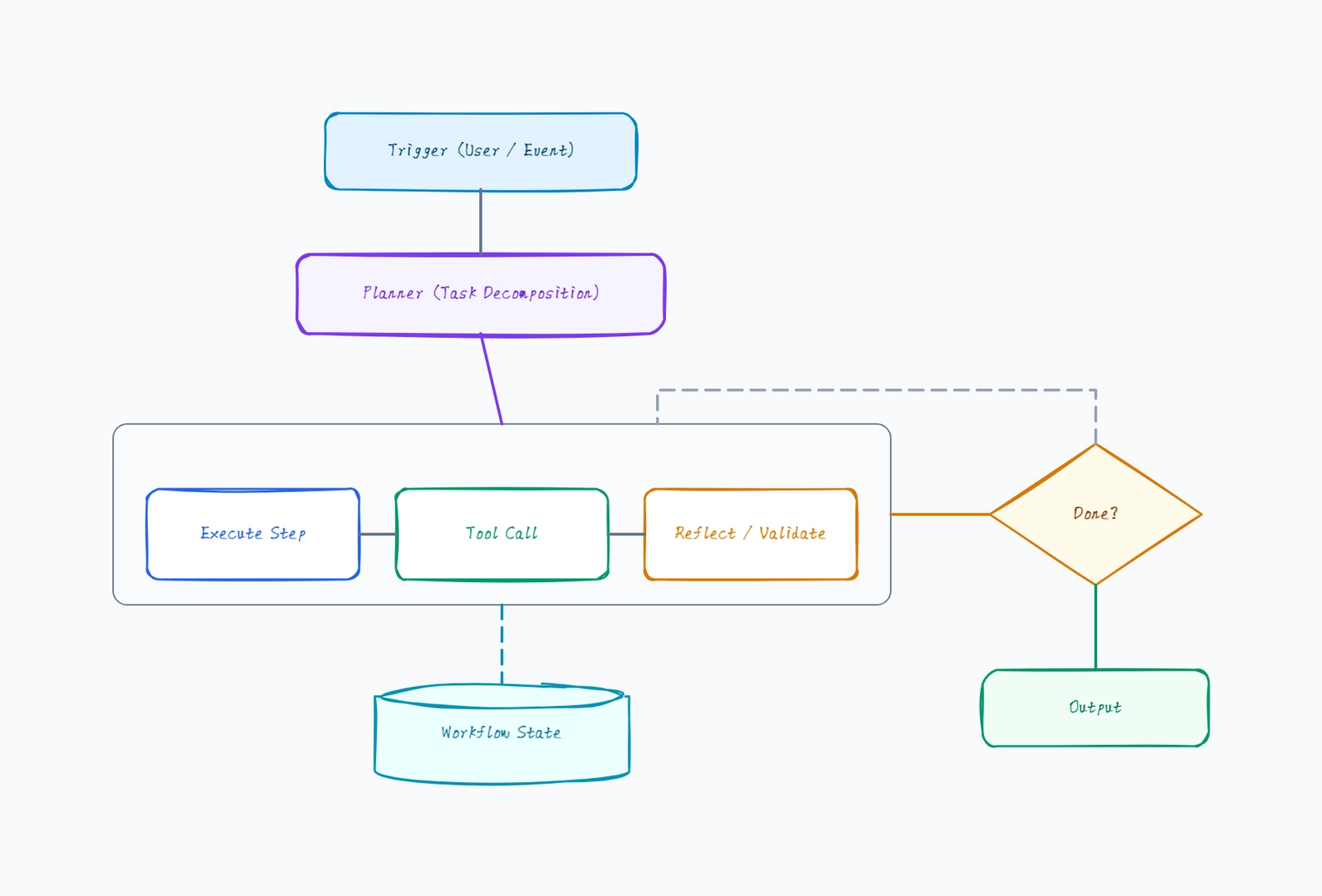
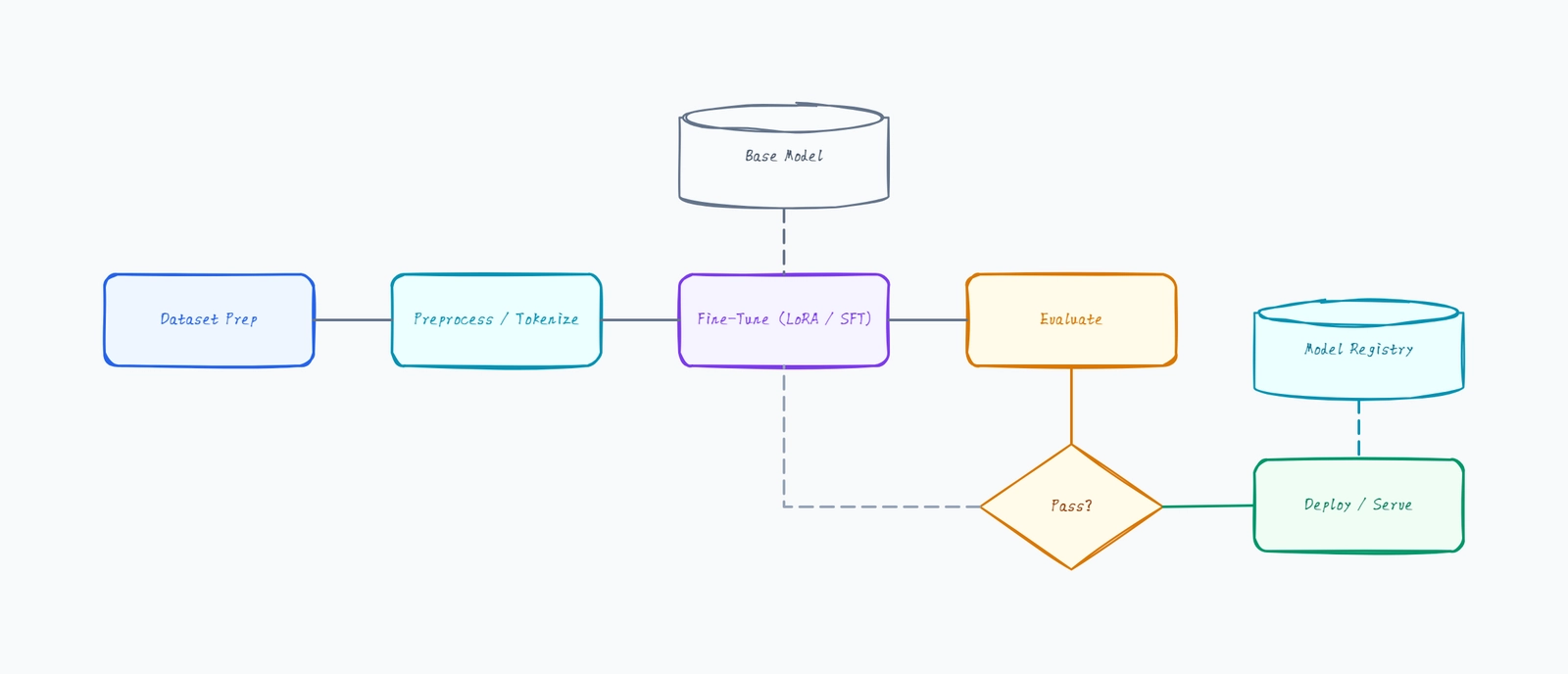
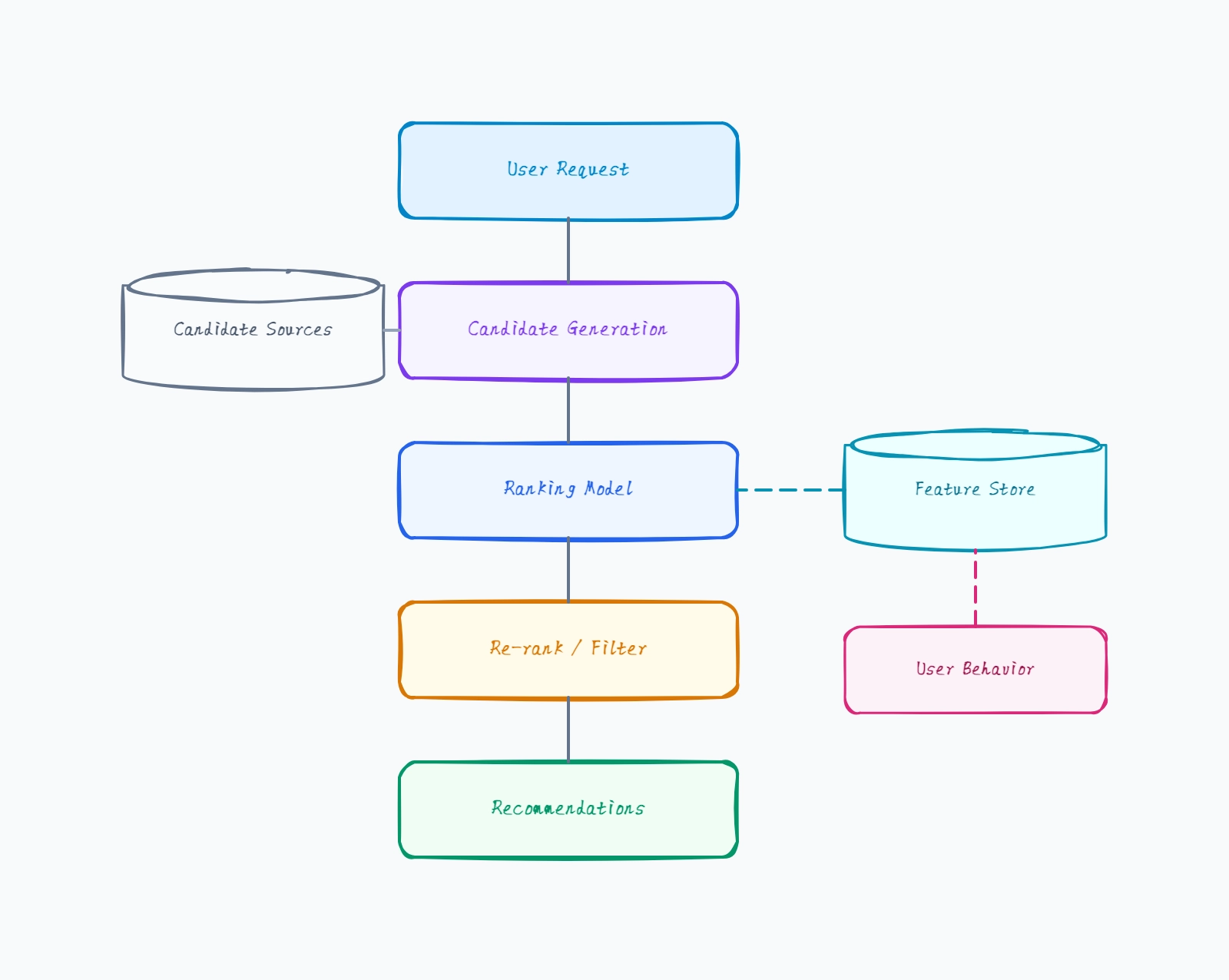
A model serving architecture diagram shows how a trained model is deployed to answer inference requests at scale. This template lays out the production serving stack: a client, an API gateway / load balancer, an inference serving cluster of model replicas with a batch queue, a model registry that loads versioned models, a result cache, and monitoring. Use it to design an ML inference service, document an existing serving setup, or explain where batching, caching, and autoscaling fit in the request path.
When to use this template
- Design a model serving stack before deploying a trained model to production.
- Explain how request batching improves GPU utilization on the inference replicas.
- Document where the model registry loads versioned models into serving.
- Show where caching short-circuits inference for repeated requests.
- Plan autoscaling by identifying which component scales under load.
- Compare a single-replica deployment against a load-balanced cluster.
How to use it
- 1Start with the client sending an inference request.
- 2Add an API gateway / load balancer that fronts the serving cluster.
- 3Add the inference serving cluster: a batch queue plus model replicas.
- 4Add a model registry below that loads versioned models into the replicas.
- 5Add a result cache beside the gateway to short-circuit repeated requests.
- 6Add monitoring connected to the serving cluster for latency and error tracking.
Quick example
GPU inference service
Start editing online
Open the template in CodePic, replace the sample nodes, and turn it into your own study board in a few minutes.
See examples: /templates/model-serving-architecture/examples