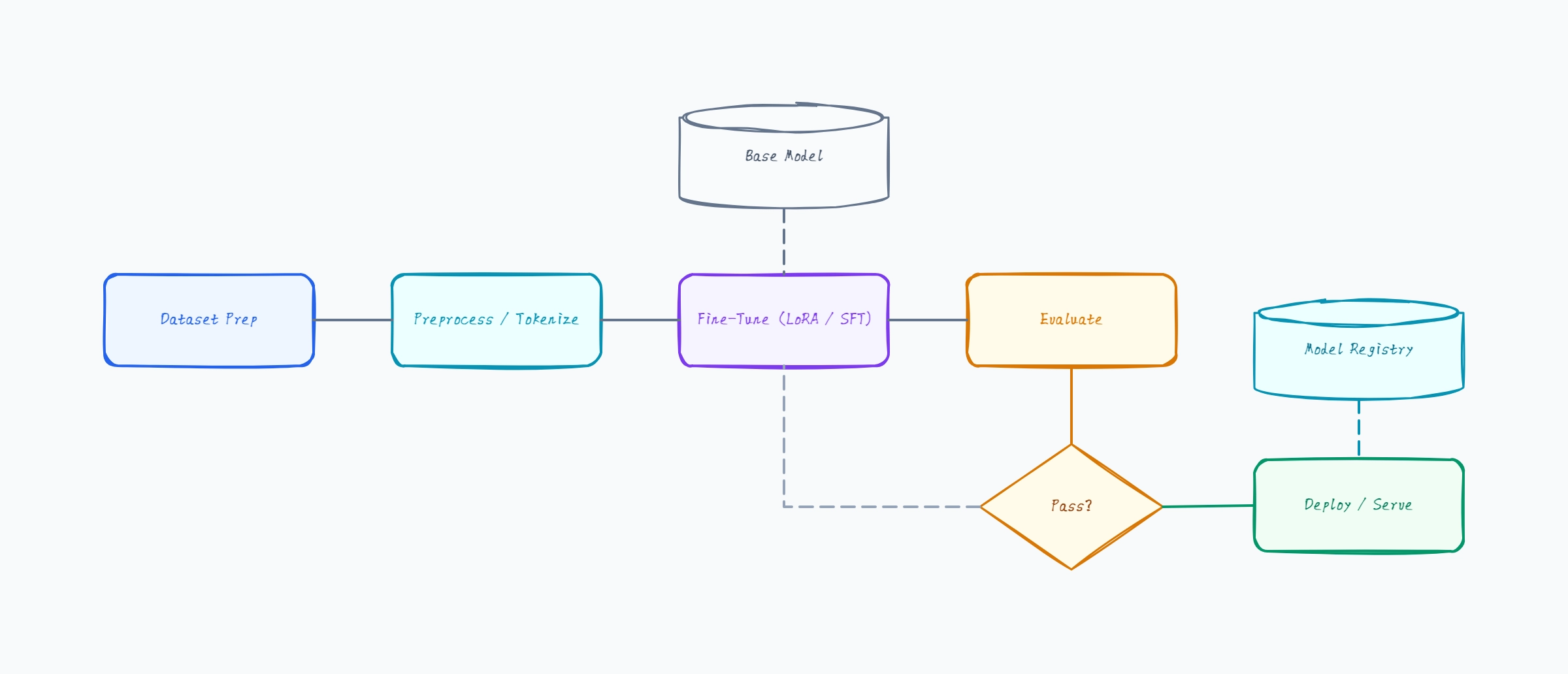
LoRA fine-tuning (parameter-efficient)
Who uses it: Developer fine-tuning on a single GPU
Base model frozen; only small adapter weights train
Dataset: a few thousand task-specific examples
Training fits on one consumer or cloud GPU
Output: a small LoRA adapter, not a full model copy
Deploy: base model + adapter loaded at serve time
Why this works: LoRA is the most accessible fine-tuning method — the diagram shows the base model frozen and only adapters training, which is why it fits on modest hardware and produces a small, swappable adapter instead of a full model.
Full supervised fine-tuning (SFT)
Who uses it: Team with budget to update all model weights
All model parameters are updated during training
Requires multi-GPU and a larger curated dataset
Checkpoints saved at intervals to the registry
Heavier eval: regression tests against base capabilities
Output: a full fine-tuned model artifact
Why this works: Full SFT updates every weight — the diagram adds checkpointing and regression eval because changing all parameters risks degrading the base model's general abilities, which must be measured before deploying.
Preference tuning (RLHF / DPO)
Who uses it: Team aligning a model to human preferences
Stage 1: SFT on demonstration data
Stage 2: collect preference pairs (chosen vs rejected)
Stage 3: DPO or RLHF optimizes against preferences
Reward model (for RLHF) or direct optimization (DPO)
Eval: win-rate against the SFT baseline
Why this works: Preference tuning adds a second training stage after SFT — the diagram shows preference data and a reward signal, because aligning to human preference is a distinct objective from imitating demonstrations.
Continuous fine-tuning
Who uses it: Team retraining as new data arrives
Production feedback feeds back into the dataset
Scheduled retraining on the growing dataset
Each run evaluated against the live model
Champion-challenger: new model must beat current
Automatic rollback if eval regresses
Why this works: Continuous fine-tuning closes the loop from production back to training — the diagram adds a feedback path and a champion-challenger gate, so a new model only replaces the live one when it measurably wins.