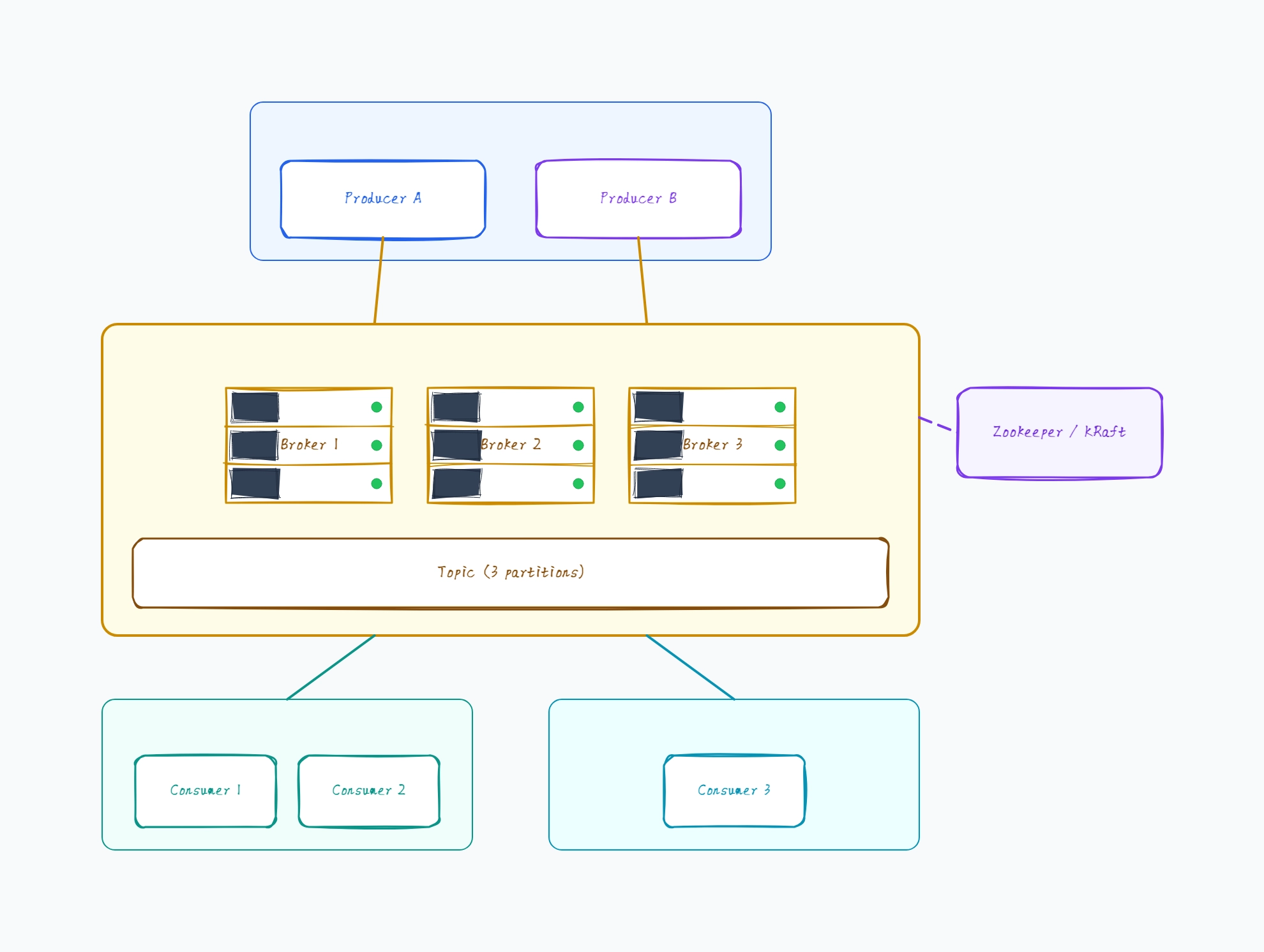
Single-broker (development only)
Who uses it: Developer running Kafka locally
One broker, no replication
Topic with 1-3 partitions for parallelism
Producer and consumer on the same machine
Zookeeper or KRaft on the same node
Acceptable for development, never for production
Why this works: Single-broker Kafka is for local development — the diagram has no replication or failover. The moment you go to production, this becomes the baseline you upgrade away from.
Replicated production cluster
Who uses it: Team deploying Kafka to production
3+ brokers with replication factor 3
Each partition has a leader and 2 followers across different brokers
Producer acks=all waits for replication before confirming
Broker failure: another replica is elected leader automatically
KRaft (newer) replaces Zookeeper for metadata
Why this works: Production Kafka requires replication — the diagram shows partitions spread across brokers with a leader/follower split, which is what survives broker failure without data loss.
Multi-topic with consumer groups
Who uses it: Team running many event types on one cluster
Multiple topics (orders, payments, inventory)
Each topic has its own partition count
Different consumer groups subscribe to different topics
A service can be a producer for one topic and consumer of another
Group rebalancing happens when consumers join/leave
Why this works: Multi-topic is the typical production shape — the diagram has several topics each with their own subscribers, and consumer-group rebalancing is the mechanism that redistributes partitions when scaling.
Kafka Streams (stateful processing)
Who uses it: Team building stream processing on top of Kafka
Kafka Streams app reads from input topic, writes to output topic
State stores (RocksDB) per partition, backed by changelog topics
Exactly-once processing semantics available
Scales by adding more application instances
No separate processing cluster needed
Why this works: Kafka Streams turns Kafka itself into a stream processor — the diagram adds a streams application between input and output topics, with per-partition state in changelog topics, eliminating the need for a separate Flink or Spark cluster.