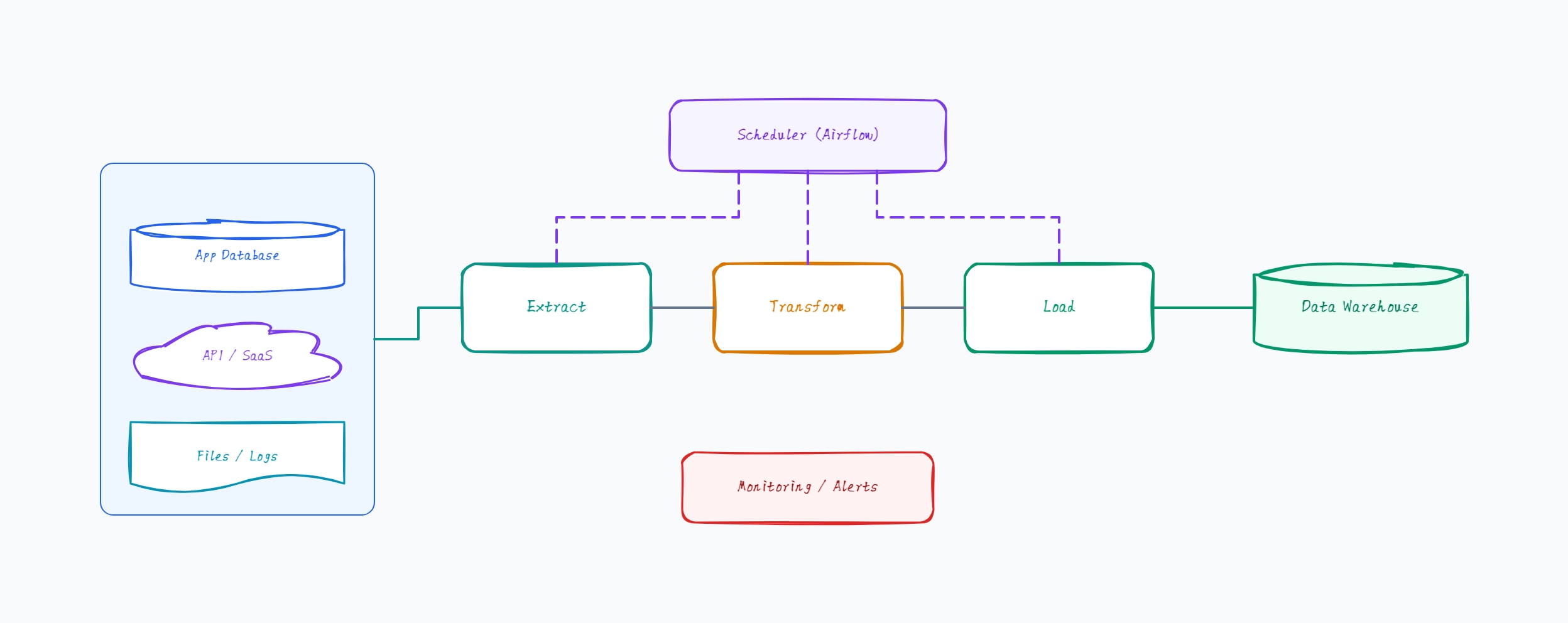
Classic batch ETL (the baseline)
Who uses it: Team building a first analytics pipeline
Scheduled hourly or nightly job
Extract from sources into a staging area
Transform in the pipeline (Spark, Pandas, dbt models pre-load)
Load only clean, modeled data into the warehouse
Warehouse stays small and clean
Why this works: Classic batch ETL transforms before load — the diagram shows transformation as a discrete stage, which keeps the warehouse minimal but pushes complexity into the pipeline tooling.