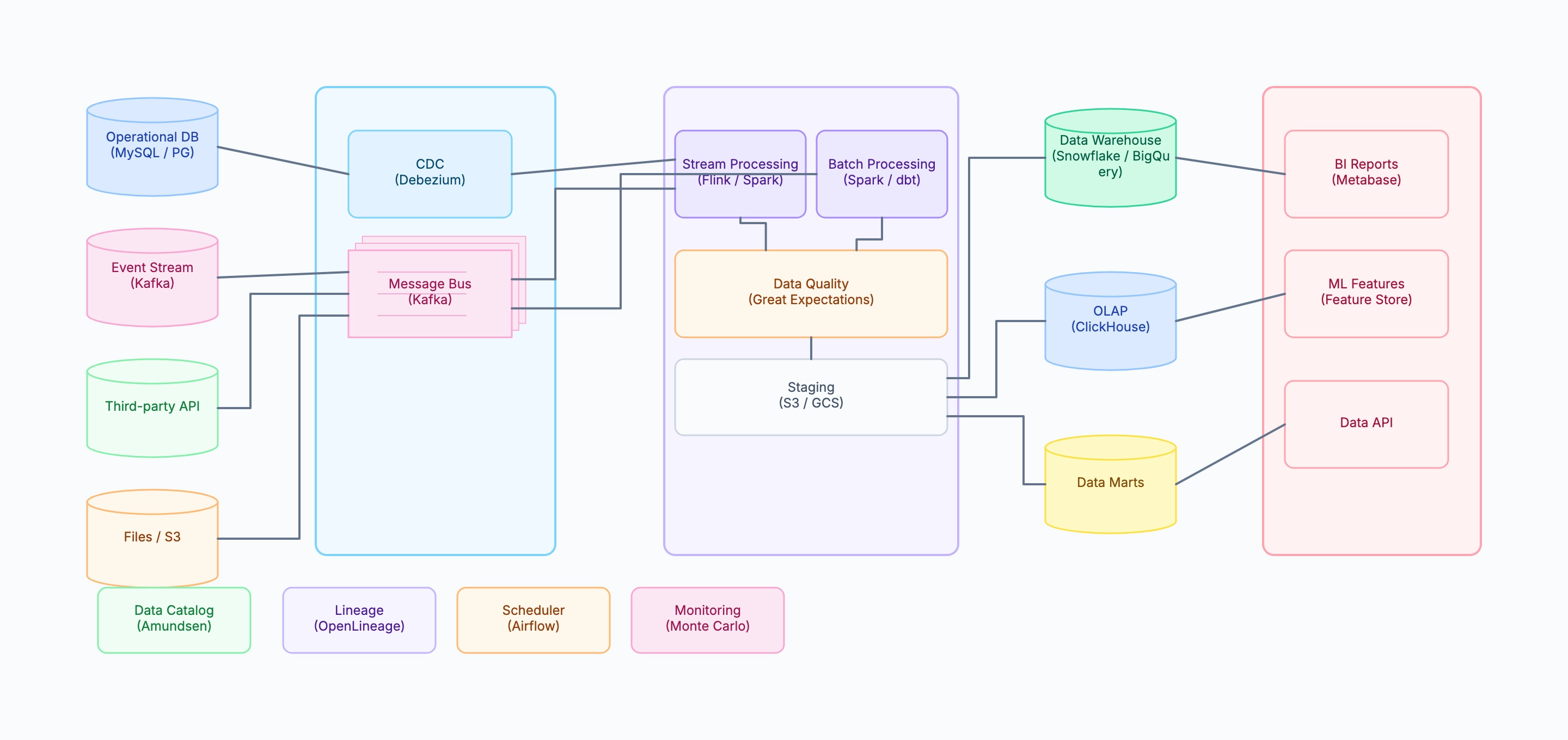
E-commerce analytics platform
Who uses it: Data engineer at a mid-size e-commerce company handling 1M+ orders/day
Sources: MySQL (orders, products), Kafka (clickstream events), Stripe webhook, S3 (application logs)
Ingestion: Debezium CDC → Kafka; Kafka consumer → S3 raw zone
Transform: Spark batch job runs every hour; dbt models transform raw → analytics
Quality: Great Expectations suite on row count, null rates, revenue totals
Warehouse: Snowflake with raw / staging / analytics / marts schema layers
Serving: Metabase dashboards, Feast ML features, internal data API
Governance: dbt docs as catalog, Monte Carlo for anomaly detection
Why this works: Separating raw, staging, and analytics schema layers in the warehouse means a broken transformation job only affects downstream consumers of that layer — the raw data remains intact and can be re-processed without re-ingestion.