托管向量数据库(Pinecone 式)
使用场景: 想要向量检索但不想运维基础设施的开发者
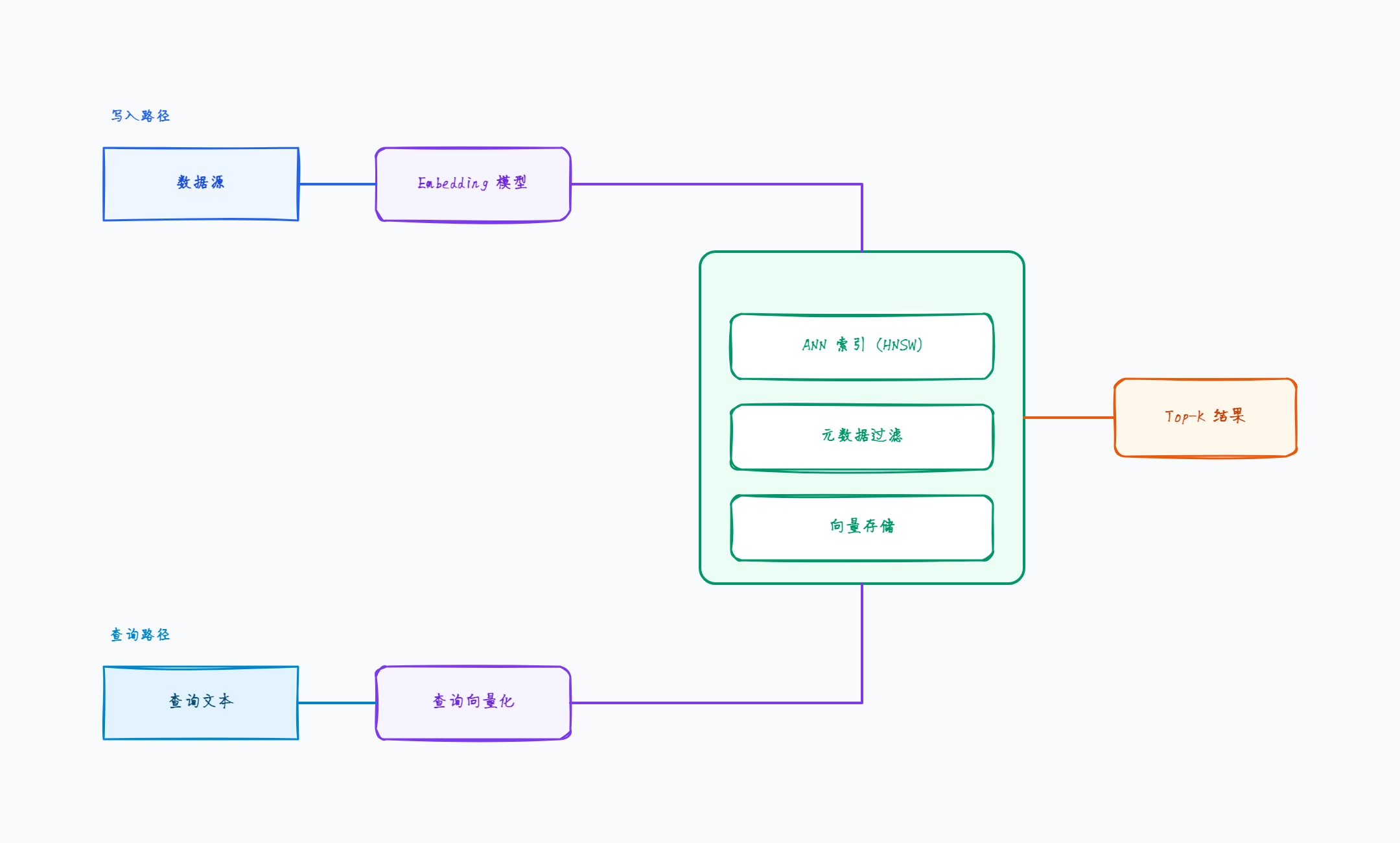
应用调用托管 API 进行 upsert 和查询
索引、存储和扩缩容由服务商处理
支持元数据过滤与向量相似度并用
Embedding 模型在应用里运行,不在数据库里
命名空间在一个索引内隔离租户
这样组织的原因: 托管向量数据库是最快的上线路径——图表最简单,因为索引、存储和扩缩容收拢进一个服务商框里,你只需负责 Embedding 步骤。
使用场景: 想要向量检索但不想运维基础设施的开发者
这样组织的原因: 托管向量数据库是最快的上线路径——图表最简单,因为索引、存储和扩缩容收拢进一个服务商框里,你只需负责 Embedding 步骤。
使用场景: 希望向量与现有关系数据放在一起的团队
这样组织的原因: 当向量本应与现有数据在一起时,用 pgvector 自托管更优——图表把向量存储折进你的主数据库,无需单独系统去同步,代价是自己管理 ANN 调优。
使用场景: 纯向量检索漏掉精确词条的团队
这样组织的原因: 混合检索在 ANN 索引旁加一个关键词索引——图表展示两条检索路径汇聚到一个融合步骤,这是抓住纯 Embedding 漏掉的精确词条(编码、名称)的方式。
使用场景: 向量达数十亿、超出单节点的团队
这样组织的原因: 超出单节点内存后分片不可避免——图表加入路由器和合并步骤,因为在数十亿向量规模下,架构既关乎 ANN 索引本身,也同样关乎 scatter-gather。
回到模板页,直接替换成你的课程主题、章节和复习重点,就可以继续使用这套结构。
使用这个模板: /editor/new?template=vector-database-architecture
编辑此向量数据库模板