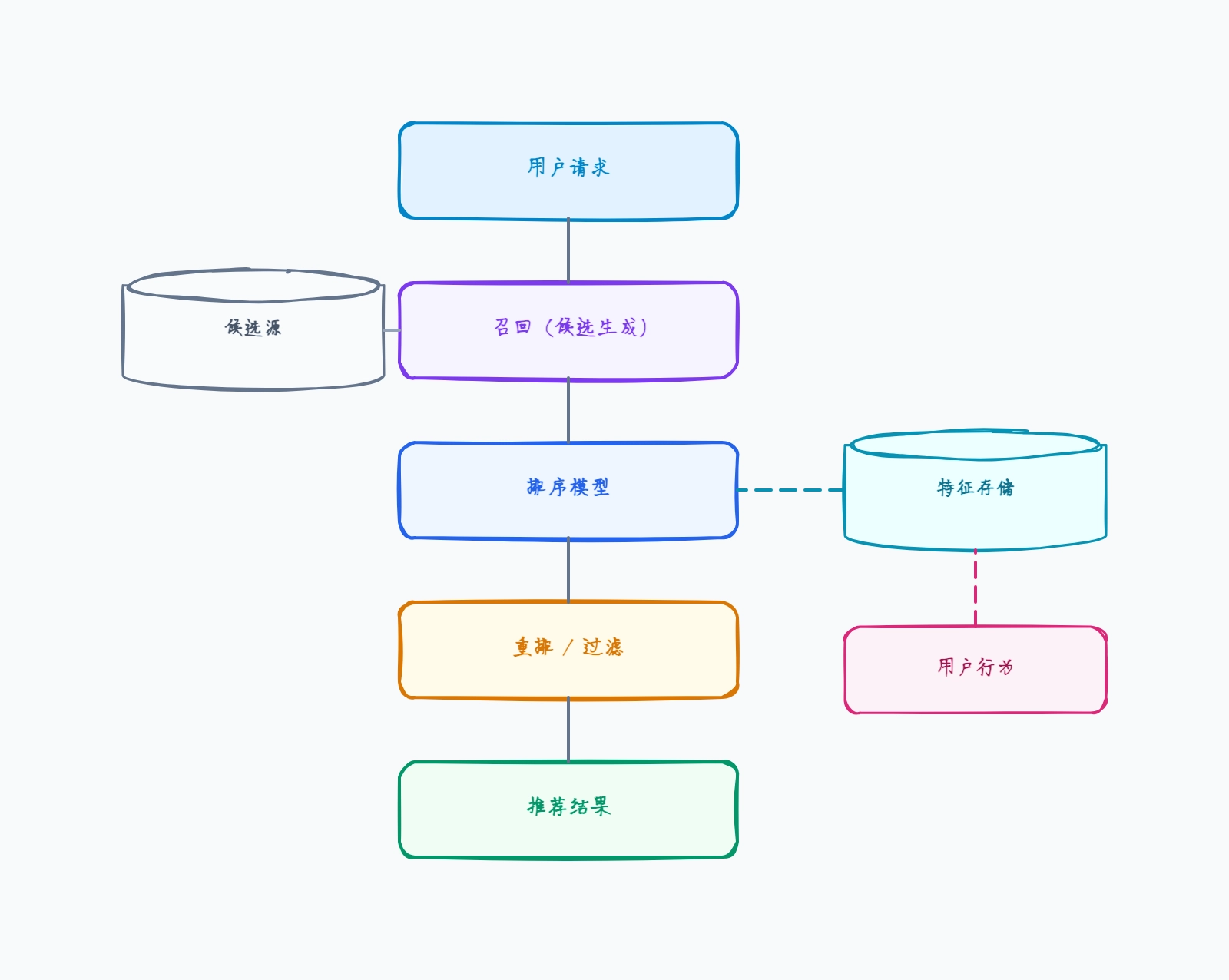
协同过滤(基线方案)
使用场景: 构建首个推荐器的开发者
候选生成:用户-物品矩阵分解
召回:相似用户喜欢的物品
排序:基于基础特征的简单 GBDT 模型
重排:过滤已看过的物品
冷启动由热门兜底处理
这样组织的原因: 协同过滤是经典起点——图表的召回阶段找出相似用户喜欢的物品,有交互数据后效果不错,但对新用户和新物品需要兜底。
使用场景: 构建首个推荐器的开发者
这样组织的原因: 协同过滤是经典起点——图表的召回阶段找出相似用户喜欢的物品,有交互数据后效果不错,但对新用户和新物品需要兜底。
使用场景: 把召回扩展到数百万物品的团队
这样组织的原因: 双塔召回把召回变成向量检索来扩展——图表增加 Embedding 索引,因为大规模下为每个物品打分不可行,于是召回变成对预计算物品向量的 ANN 查找。
使用场景: 用新鲜信号提供推荐的团队
这样组织的原因: 实时推荐器增加流式特征路径——图表把特征存储拆为在线和离线,因为最新的会话内行为必须在请求的延迟预算内到达排序模型。
使用场景: 用 LLM 排序或解释推荐的团队
这样组织的原因: 基于 LLM 的推荐器通常保留传统召回,把 LLM 放在排序 / 解释阶段——图表展示 LLM 对召回的候选列表重排,因为对整个目录跑 LLM 会太慢太贵。
回到模板页,直接替换成你的课程主题、章节和复习重点,就可以继续使用这套结构。
使用这个模板: /editor/new?template=recommendation-system-architecture
编辑此推荐系统模板