电商分析平台
使用场景: 处理每日百万级订单的中型电商数据工程师
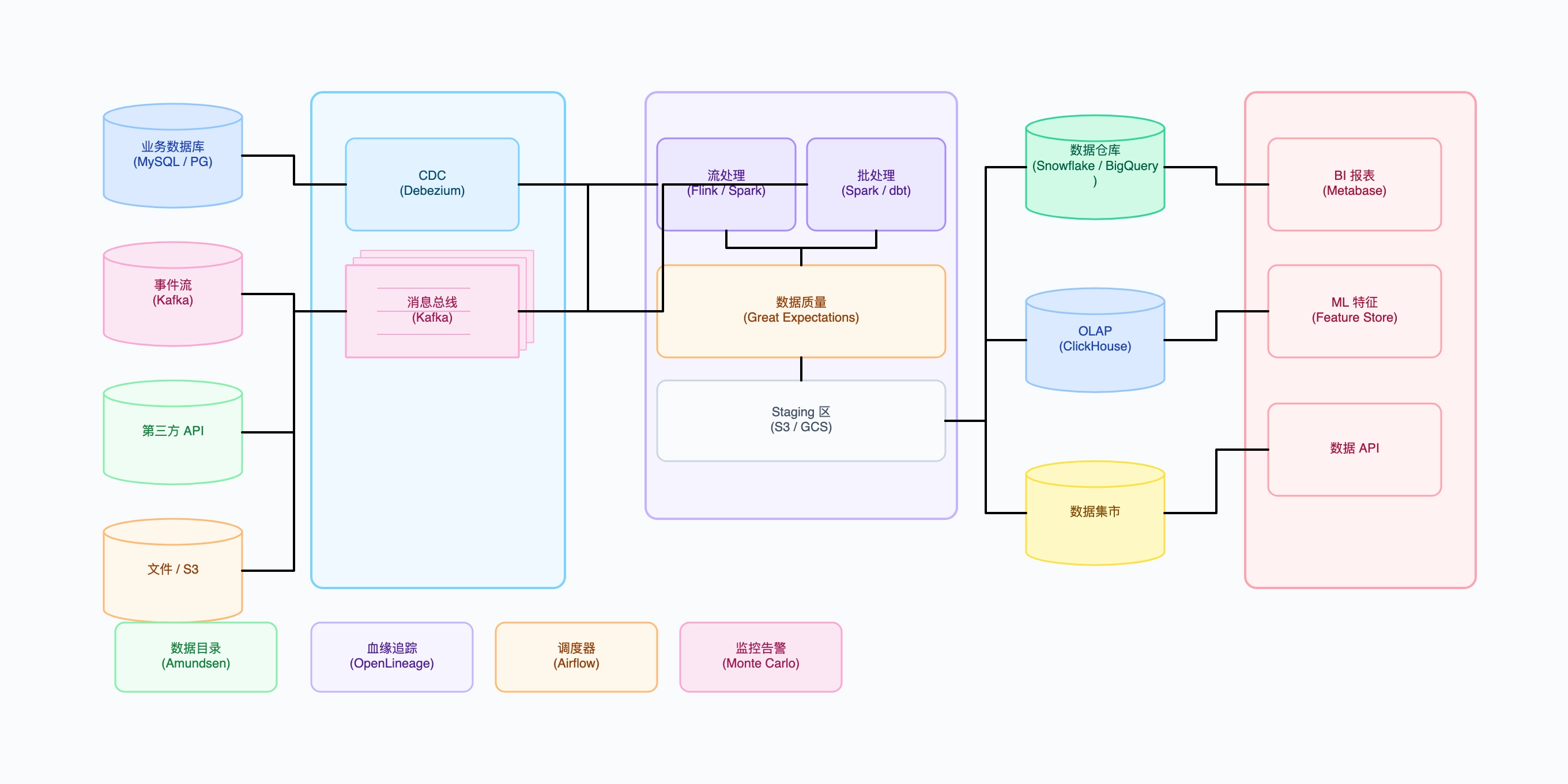
数据源:MySQL(订单/商品)、Kafka(点击流)、Stripe Webhook、S3(应用日志)
摄入:Debezium CDC → Kafka;Kafka Consumer → S3 原始区
转换:每小时 Spark 批处理;dbt 模型将 raw 转为 analytics
质量:Great Expectations 检查行数、空值率、营收总额
数仓:Snowflake,分 raw / staging / analytics / marts 层
服务:Metabase 仪表板、Feast ML 特征、内部数据 API
治理:dbt docs 作为数据目录,Monte Carlo 做异常检测
这样组织的原因: 在数仓中将 raw、staging 和 analytics 分层意味着转换作业出错只影响该层的下游消费者——原始数据保持完整,可以在不重新摄入的情况下重新处理。