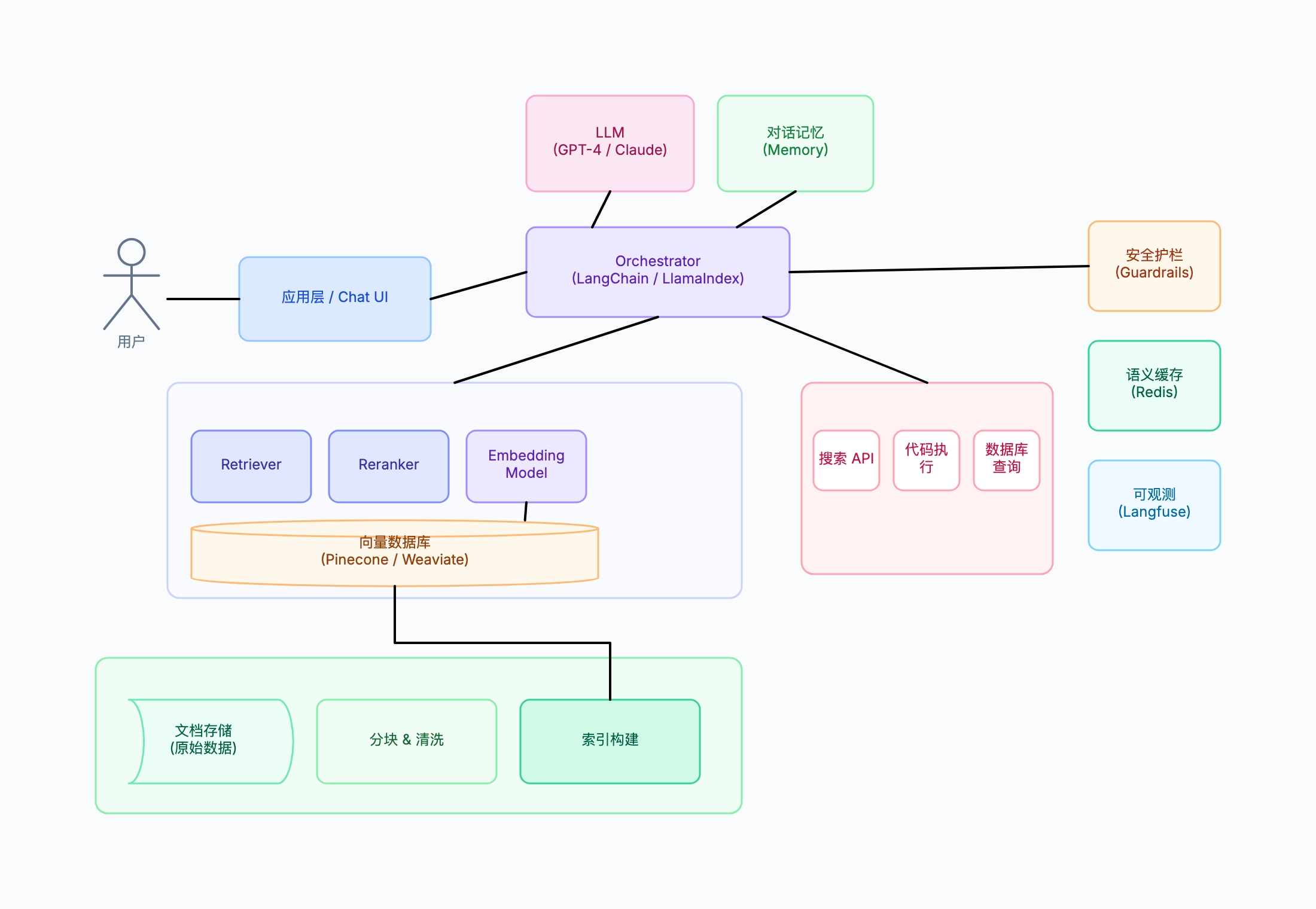
企业内部文档问答系统(RAG)
使用场景: 构建内部知识库聊天机器人的 ML 工程师
摄入:SharePoint/Confluence → 分块(512 tokens)→ Embedding → Weaviate
查询路径:用户问题 → Embedding → 向量检索(Top-20)→ 重排序(Top-5)→ GPT-4
编排器:LangChain,对话历史存入 PostgreSQL
护栏:输入端 PII 检测,输出端引用来源校验
缓存:精确匹配 Redis + 语义相似度缓存
可观测性:Langfuse 追踪 LLM 调用,按部门统计成本
这样组织的原因: 企业级 RAG 需要完整的技术栈:护栏阻止敏感数据到达 LLM,重排序在大规模语料库中提升精度,按部门的成本追踪帮助证明基础设施投入的合理性。