基于 RAG 的客服机器人
使用场景: 在帮助中心文档之上构建聊天机器人的团队
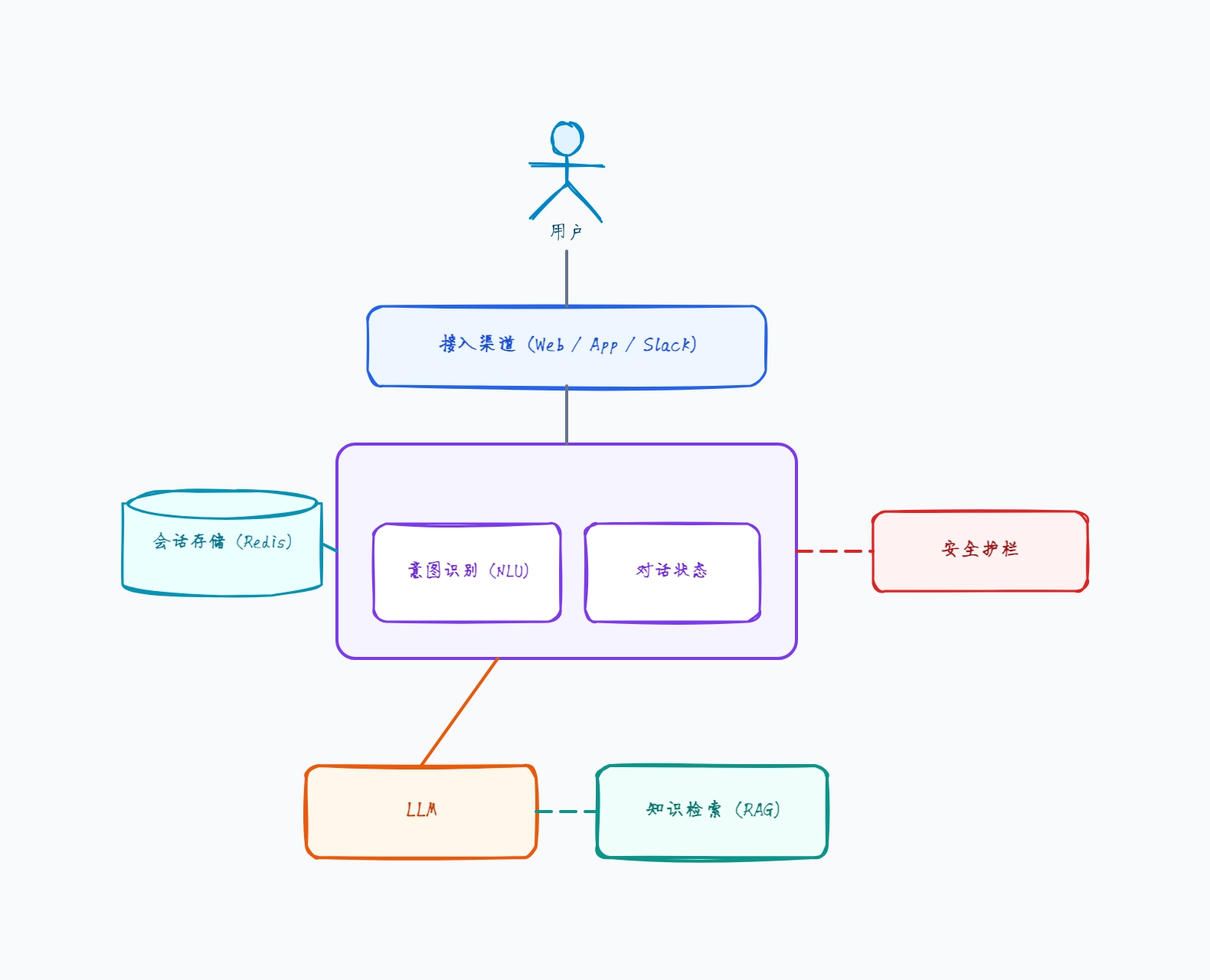
渠道:网站组件 + 应用内聊天
对话管理把每条消息路由给 LLM
RAG 在生成前检索相关帮助文章
护栏:输入端 PII 脱敏,输出端引用校验
会话存储保持对话线程
这样组织的原因: RAG 客服机器人是最常见的生产模式——把每个答案建立在检索到的文档之上,是防止机器人自信地编造政策的关键,图表应展示检索发生在生成之前。
以下聊天机器人示例展示了同样的「渠道—对话—LLM」骨架如何适配不同产品——基于 RAG 的客服机器人、经典意图机器人、多渠道助手和语音前端。
使用场景: 在帮助中心文档之上构建聊天机器人的团队
这样组织的原因: RAG 客服机器人是最常见的生产模式——把每个答案建立在检索到的文档之上,是防止机器人自信地编造政策的关键,图表应展示检索发生在生成之前。
使用场景: 有明确定义流程(预订、FAQ、状态查询)的团队
这样组织的原因: 基于意图的设计适合需要确定性流程的有界任务——图表以 NLU 分类器和脚本化对话为中心,LLM 作为兜底而非核心,用灵活性换取可控性。
使用场景: 用一个机器人服务 Web、移动端和 Slack 的团队
这样组织的原因: 多渠道助手把渠道适配器与核心分离——图表展示多个前端收拢进一个对话管理,业务逻辑只存在一次,每个渠道只处理自己的格式。
使用场景: 添加语音交互界面的团队
这样组织的原因: 语音机器人在文本架构外面包一层 STT 和 TTS——图表清楚表明对话核心完全相同,变化的只是输入 / 输出的转换和延迟预算。
回到模板页,直接替换成你的课程主题、章节和复习重点,就可以继续使用这套结构。
使用这个模板: /editor/new?template=ai-chatbot-architecture
编辑此 AI 聊天机器人模板