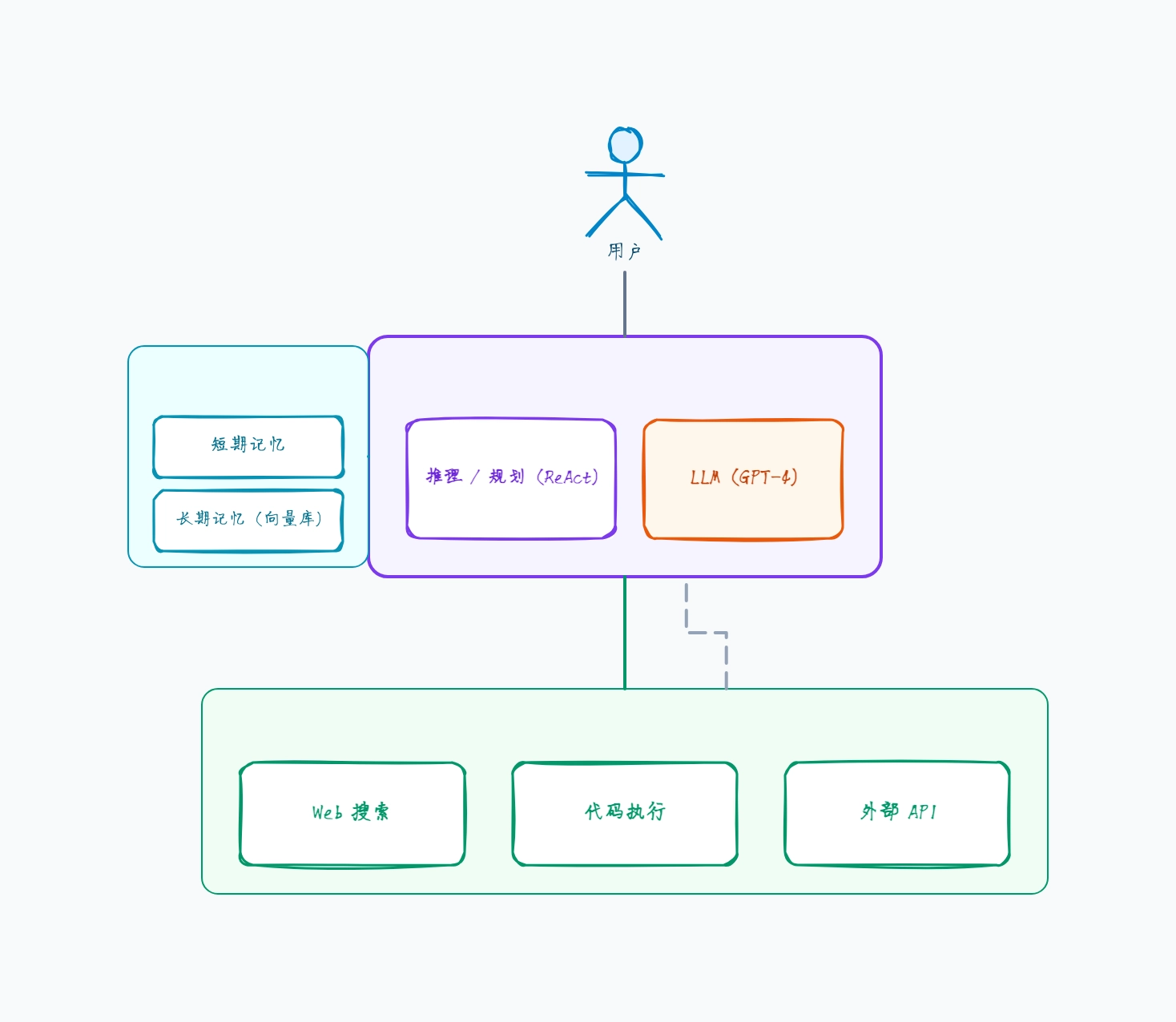
ReAct Agent(推理 + 行动)
使用场景: 构建首个工具调用 Agent 的开发者
循环:思考 → 行动 → 观察 → 重复,直到得出答案
LLM 在每一步决定是调用工具还是结束
工具:搜索、计算器、单个外部 API
记忆:保存本次任务推理轨迹的暂存区
当 LLM 输出最终答案而非行动时停止
这样组织的原因: ReAct 是默认的起步模式——Agent 在一个循环里交替推理和工具调用,所以出问题时你能直接读它的暂存区,看清它为何选择每一步行动。
以下 AI Agent 示例展示了同样的构建块——推理循环、LLM、记忆和工具——如何为不同的 Agent 模式组合,从简单的工具调用者到把工作拆成步骤的规划 Agent。
使用场景: 构建首个工具调用 Agent 的开发者
这样组织的原因: ReAct 是默认的起步模式——Agent 在一个循环里交替推理和工具调用,所以出问题时你能直接读它的暂存区,看清它为何选择每一步行动。
使用场景: 任务步骤多、容易跑偏的工程师
这样组织的原因: 先规划后执行把「做什么」和「怎么做」分开——任务很长时很有用,因为 Agent 一开始就锁定一个计划,而不是每一步都重新决定整体策略。
使用场景: 构建能跨会话记住用户的 Agent 的团队
这样组织的原因: 记忆增强是把无状态聊天机器人变成「像是认识你」的助手的关键——先检索、后写入的模式既保持提示词精简,又让 Agent 能访问它学到的一切。
使用场景: 跨数据源自动化收集数据的分析师
这样组织的原因: 多工具 Agent 在没有单一数据源能给出答案时最有用——价值在于 Agent 为每个子问题选对工具并整合结果,而这正是图表应当清晰呈现的。
回到模板页,直接替换成你的课程主题、章节和复习重点,就可以继续使用这套结构。
使用这个模板: /editor/new?template=ai-agent-architecture
编辑此 AI Agent 模板